作業系統,虛擬化、並行與持久化
深入解析作業系統如何管理電腦資源,讓多個程式順暢地同時運行。
作業系統(Operating System, OS)是電腦系統的基石,扮演著資源管理者的關鍵角色。 它的核心任務是作為使用者與底層硬體之間的中介,讓使用者可以方便、有效地使用硬體資源,同時也讓硬體能根據使用者需求,為指定的服務做好準備。
各位必定寫過程式,當程式被執行時,它會被載入到記憶體中,成為一個「處理程序」(Process)。然而,電腦的硬體資源(如 CPU、記憶體)是有限的,但我們希望運行的程式卻是無限的。為了解決這個矛盾,作業系統運用了一些聰明的手段。
首先,為了讓每個處理程序都擁有獨立且互不干擾的執行環境,作業系統採用了虛擬化(Virtualization)技術。 透過虛擬化,儘管所有處理程序共享著同一套硬體,但每一個程序都彷彿獨佔了整部電腦,無需擔心其他程序的存在。
然而,不論虛擬化技術如何優化,一顆 CPU 在任何一個時間點,實際上仍然只能執行一個指令。當多個處理程序都想使用 CPU 時,作業系統如何巧妙安排,讓使用者感覺所有程式都在「同時」執行,這就是並行(Concurrency)所要解決的課題。
最後,處理程序在運行過程中產生的資料或結果,例如一份文件、一張圖片,我們通常希望它們能被永久保存下來,即使關機後也不會消失。這部分則由作業系統的持久化(Persistency)機制來負責,最常見的實現就是檔案系統。
以上三大核心概念——虛擬化、並行、持久化,構成了現代作業系統的基礎。接下來,我們將逐一深入探討。
虛擬化
作業系統的核心職責之一,就是為每個處理程序創造一個獨立的執行假象,讓它們都以為自己獨佔了所有硬體資源。 為此,OS 提供了兩大虛擬化技術:CPU 虛擬化與記憶體虛擬化。
CPU 虛擬化
CPU 虛擬化的目標,是讓每個處理程序都認為自己擁有專屬的計算單元。
事實上,單一 CPU 核心在同一時間只能執行一道指令。但作業系統的排程器(Scheduler)可以透過極快的速度在不同處理程序之間進行 上下文切換(Context Switching),造成所有程序看似同時運行的錯覺。
- 時間片(Time Slice):排程器會為每個處理程序分配一段極短的 CPU 使用時間,稱為時間片。當一個程序的時間片用完後,即使它還沒執行完畢,也會被強制暫停。
- 上下文切換:當作業系統決定切換處理程序時,它會先儲存目前正在執行程序的狀態(例如程式計數器、暫存器的值),然後載入下一個程序的狀態,讓其接續執行。這個保存與載入的過程,就是上下文切換。由於這個過程非常迅速(通常在微秒級別),使用者幾乎無法察覺。
透過「時間片」與「上下文切換」的緊密配合,作業系統便實現了 CPU 的虛擬化,達成了多工處理(Multitasking)的目標。
記憶體虛擬化
與 CPU 虛擬化類似,虛擬記憶體的目標是讓每個處理程序都認為自己擁有一段連續且完整的記憶體空間,這個空間被稱為位址空間(Address Space)。 這不僅能保護各個程序的記憶體不被非法存取,也解決了實體記憶體碎片化的問題。
實際上,程式所看到的「虛擬位址」並非真正的實體記憶體位址。作業系統透過 CPU 內建的記憶體管理單元(Memory Management Unit, MMU),將虛擬位址轉譯為實體的記憶體位址。 這個轉譯的對照表,就是頁表(Page Table)。
流程大致如下: 虛擬位址 (Virtual Address) -> 虛擬頁面 (Virtual Page) -> 實體頁框 (Physical Page Frame)
- 拆分位址:當 CPU 要存取一個虛擬位址時,MMU 會根據頁面大小(Page Size),將虛擬位址拆分為虛擬頁碼(VPN)和頁內偏移量(VPO)。
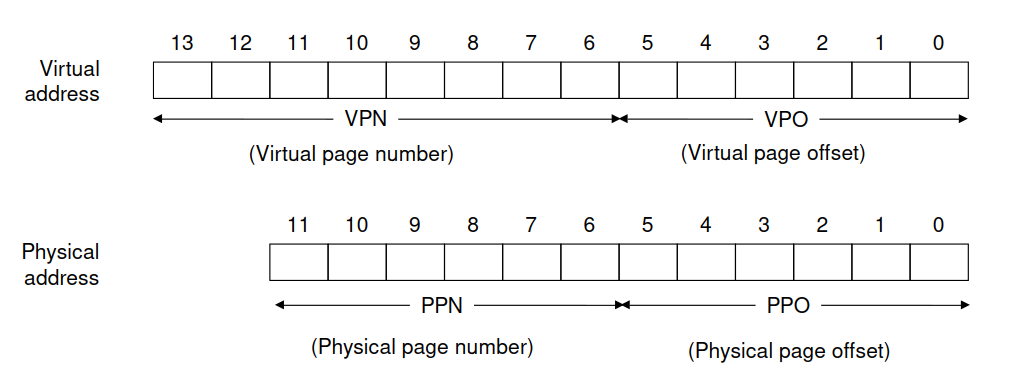 Addressing for Small Memory System. Source: https://csapp.cs.cmu.edu/3e/ics3/vm/ataddr.pdf
Addressing for Small Memory System. Source: https://csapp.cs.cmu.edu/3e/ics3/vm/ataddr.pdf
- 查詢 PPN:MMU 的核心任務是根據 VPN 找到對應的實體頁框碼(PPN)。
- 首先,MMU 會檢查一組名為變換後備緩衝區(Translation Lookaside Buffer, TLB)的高速快取。TLB 儲存了最近使用過的 VPN 到 PPN 的對應紀錄。如果命中(TLB Hit),就能立刻得到 PPN,速度非常快。
- 如果 TLB 未命中(TLB Miss),MMU 就必須去查詢儲存在主記憶體中的頁表,從中找出 VPN 對應的 PPN。
- 如果在頁表中發現該頁面是無效的(Invalid),代表該頁面對應的資料目前不在實體記憶體中(可能還在硬碟裡)。此時 MMU 會觸發一個名為「分頁錯誤」的中斷。 作業系統會接管,從磁碟中找到對應的資料載入到實體記憶體的一個可用頁框中,然後更新頁表和 TLB,最後重新執行被中斷的指令。
- 組合實體位址:一旦 MMU 取得了 PPN,就會將 PPN 與原本的頁內偏移量(VPO)組合成最終的實體位址,然後到該位址存取資料。
- CPU 快取:在存取主記憶體(DRAM)前,系統會先檢查 CPU 的多層快取(Cache),若資料存在,則直接取用。
- 主記憶體:若快取中沒有,才會前往 DRAM 存取。
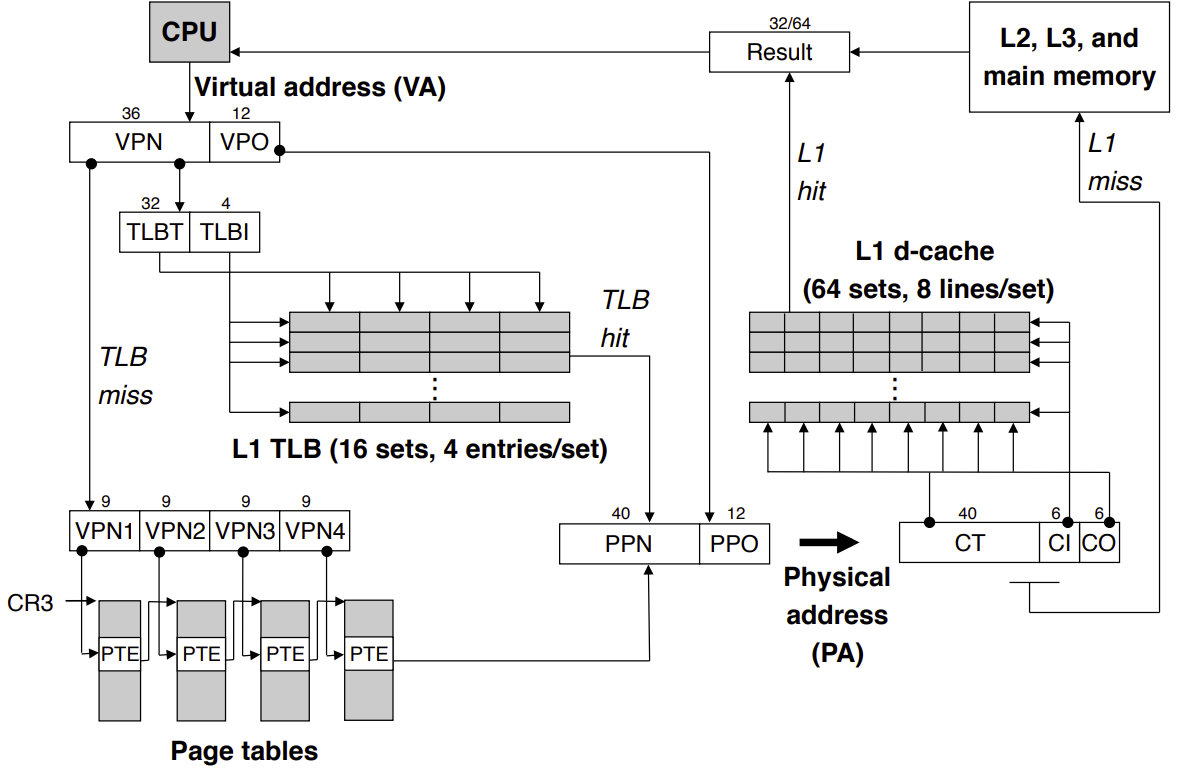 Summary of Address Translation. Source: https://csapp.cs.cmu.edu/3e/ics3/vm/corei7addrtrans.pdf
Summary of Address Translation. Source: https://csapp.cs.cmu.edu/3e/ics3/vm/corei7addrtrans.pdf
這個複雜但高效的機制,讓應用程式開發者無需關心實體記憶體的管理,同時也極大地提升了記憶體的使用效率與系統的安全性。
並行
並行(Concurrency)與 CPU 虛擬化息息相關,其核心議題是 CPU 排程(CPU Scheduling)。 當系統中有多個處理程序都處於可以執行的狀態時,作業系統的排程器(Scheduler)必須決定下一個要執行哪一個程序,以及執行多久。
現代作業系統的排程器通常會融合多種標準,以達到效能與公平性的平衡。常見的排程演算法包括:
- 先進先出(First-Come, First-Served, FCFS):最單純的演算法,如同排隊,先來的程序先執行。缺點是若一個長時間的程序先來,後面的短程序就必須漫長等待。
- 最短工作優先(Shortest Job First, SJF):優先執行預估執行時間最短的程序,能有效降低平均等待時間。
- 優先權排程(Priority Scheduling):為每個程序指定一個優先權,優先權最高的先執行。為避免低優先權的程序永遠等不到 CPU(稱為飢餓 Starvation),通常會搭配「老化」(Aging)機制,逐漸提升等待已久程序的優先權。
- 循環法(Round Robin, RR):每個程序被給予一個固定的時間片,時間一到就換下一個程序,非常適合分時系統。
為了有效管理,作業系統會將處理程序劃分為三種主要狀態:
- 就緒(Ready):萬事具備,只等待排程器分配 CPU 資源。
- 執行(Running):正在 CPU 上執行指令。
- 等待(Waiting / Blocked):程序正在等待某個外部事件完成,例如等待使用者輸入、網路封包或檔案讀取。處於此狀態的程序不會佔用 CPU。
這些狀態會不斷轉換:一個程序從就緒變為執行,可能因時間片用完而回到就緒,或因發起 I/O 請求而進入等待,待 I/O 完成後再回到就緒,最終執行完畢而結束。
「你看,他媽你們作業系統花了這麼多篇幅介紹排程器,結果真的在核心裡面,排程器佔的程式碼不到 1%」
持久化
處理程序的運算過程與結果,很多時候需要被永久保存。作業系統透過檔案系統(File System)來解決持久化(Persistence)的需求。 使用者無需煩惱資料該存放在磁碟的哪個磁區、哪個磁軌,只需要告訴作業系統檔案名稱與內容,作業系統就會處理好一切。
具體來說,一個寫入檔案的動作大致包含以下步驟:
- 使用者應用程式(例如文字編輯器)透過系統呼叫
write,向作業系統核心發出寫入請求,並提供檔案描述符、資料內容與長度等資訊。 - 作業系統的檔案系統接收到請求後,會先讀取該檔案的元資料(Metadata,例如 i-node),檢查權限、檔案大小等資訊,並在磁碟上找到可用的資料塊(Data Block)來存放新的資料。
- 檔案系統將「將資料寫入某個邏輯區塊」這個高階指令,交給對應的儲存裝置驅動程式。驅動程式會將此指令翻譯成一連串該硬體裝置控制器(Device Controller)能理解的低階指令(例如,移動磁頭到某個磁軌、啟動寫入等)。
- 裝置控制器接收到指令後,便會直接操作硬體,將資料真正寫入到磁碟的實體位置上。
透過這樣層層的抽象化,應用程式開發者可以輕鬆地進行檔案操作,而無需理解底層硬體複雜的運作細節。
參考資料
- Randal E. Bryant and David R. O’Hallaron. Computer Systems: A Programmer’s Perspective, 3/e. Prentice Hall, 2015.
- Remzi H. Arpaci-Dusseau and Andrea C. Arpaci-Dusseau. Operating Systems: Three Easy Pieces.
- Abraham Silberschatz, Peter B. Galvin, and Greg Gagne. Operating System Concepts, 10th Edition. Wiley, 2021.
- 樂詞網